Introduction
Heart disease remains one of the leading causes of death globally, with 17.9 million people succumbing to cardiovascular diseases in 2019 alone. Early detection and intervention are crucial in mitigating the risks associated with heart disease. However, the healthcare sector often lacks the necessary resources to adequately address the large-scale challenges posed by this condition.
Our team has developed an advanced machine learning project aimed at improving the detection of patients at risk of heart disease. This project addresses a critical health issue and demonstrates the potential of AI in medical diagnostics, potentially reducing the burden on healthcare providers and improving patient outcomes.
Objective
The primary goals of our project were to:
- Improve the rate of success for detecting patients at risk of heart disease
- Decrease the risk of not identifying patients at risk of heart disease
- Develop machine learning models with greater efficacy than prior models
- Study and compare various models for heart disease classification
Research and Literature Review
Our project began with extensive research into heart disease and its risk factors. We conducted a comprehensive literature review to understand the current state of heart disease detection and the potential for machine learning in this field.
We utilized datasets from the University of California, Irvine repository, which included trials from the Cleveland Clinic Foundation. The dataset comprises 13 key risk factors, including age, sex, chest pain type, resting blood pressure, cholesterol levels, and more.
Experiments and Results
We conducted experiments with different optimizers and learning rates. The results are summarized in the following images:
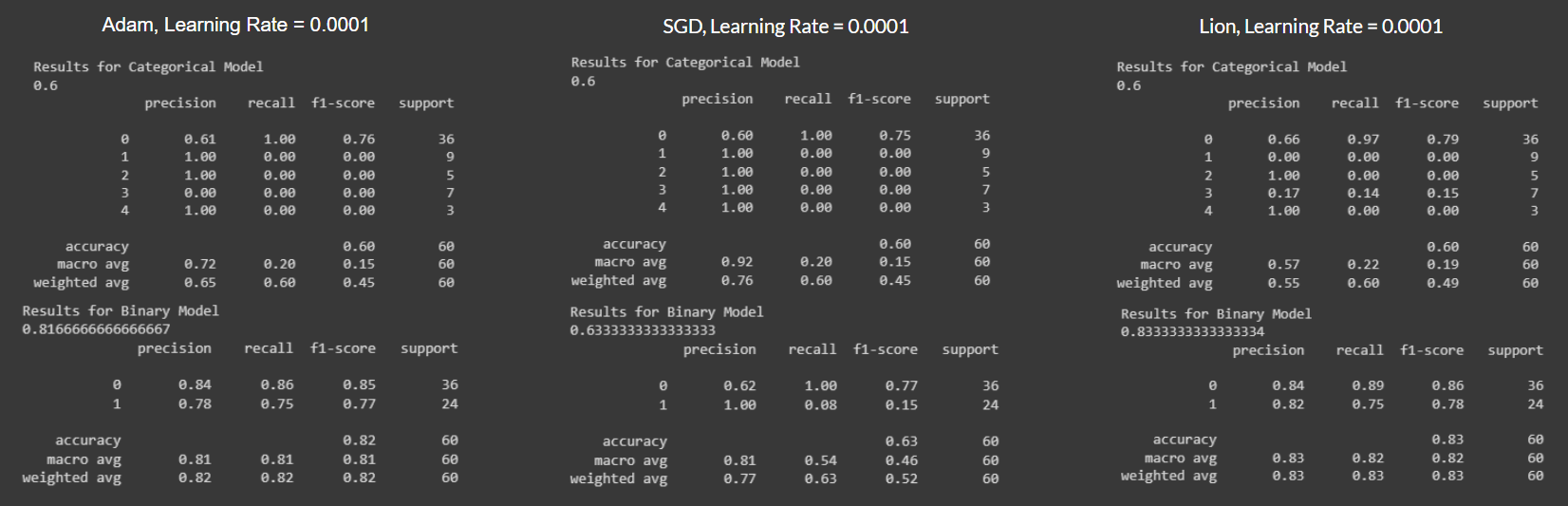 Figure 7.1: Optimizers with LR = 0.0001
Figure 7.1: Optimizers with LR = 0.0001
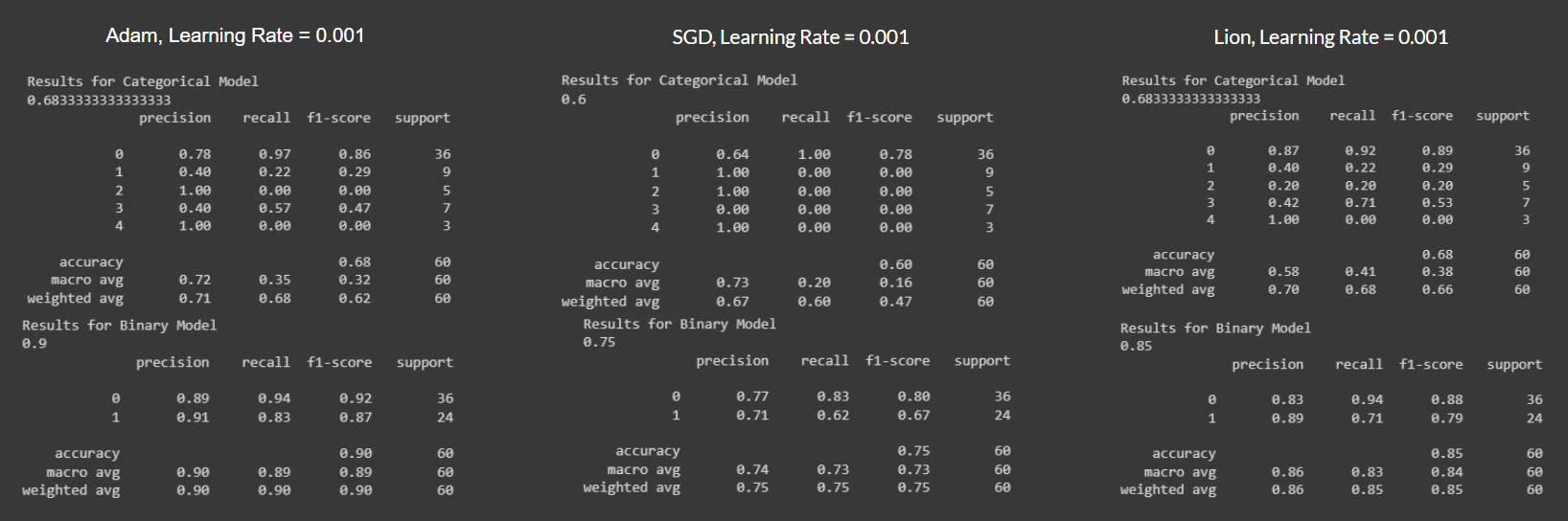 Figure 7.2: Optimizers with LR = 0.001
Figure 7.2: Optimizers with LR = 0.001
From the results above, we can see that the best optimizer to use is Adam.
Approach
Our approach involved testing various machine learning models, including:
- Recurrent Neural Networks (RNN)
- K-Nearest Neighbors (KNN)
- Support Vector Machine (SVM)
- Decision Tree Classification
- Random Forest Classification
These models were evaluated based on metrics derived from a confusion matrix, including accuracy, precision, recall, and F1-score, to determine their effectiveness in detecting heart disease.
Implementation
We implemented our models using Python, leveraging popular libraries such as TensorFlow, Keras, and scikit-learn. Here are snippets of our code for creating classification and binary models using neural networks:
Categorical Model
def create_categorical_model():
model = Sequential()
model.add(Dense(10, input_dim=13, kernel_initializer='normal', activation='relu'))
model.add(Dense(6, kernel_initializer='normal', activation='relu'))
model.add(Dense(5, activation='softmax'))
optimizer = Adam(learning_rate=0.001)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
classification_model = create_classification_model()
classification_model.fit(X_train, Y_train_classification, epochs=100, batch_size=10, verbose=1)Binary Model
def create_binary_model():
model = Sequential()
model.add(Dense(10, input_dim=13, kernel_initializer='normal', activation='relu'))
model.add(Dense(6, kernel_initializer='normal', activation='relu'))
model.add(Dense(1, activation='sigmoid'))
optimizer = Adam(learning_rate=0.001)
model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
return model
binary_model = create_binary_model()
binary_model.fit(X_train, Y_train_binary, epochs=100, batch_size=10, verbose=1)Results and Analysis
After rigorous testing and optimization, our best model achieved an impressive accuracy of 90% in detecting heart disease. We experimented with various parameters such as learning rates, optimizers, and neuron counts to achieve this result.
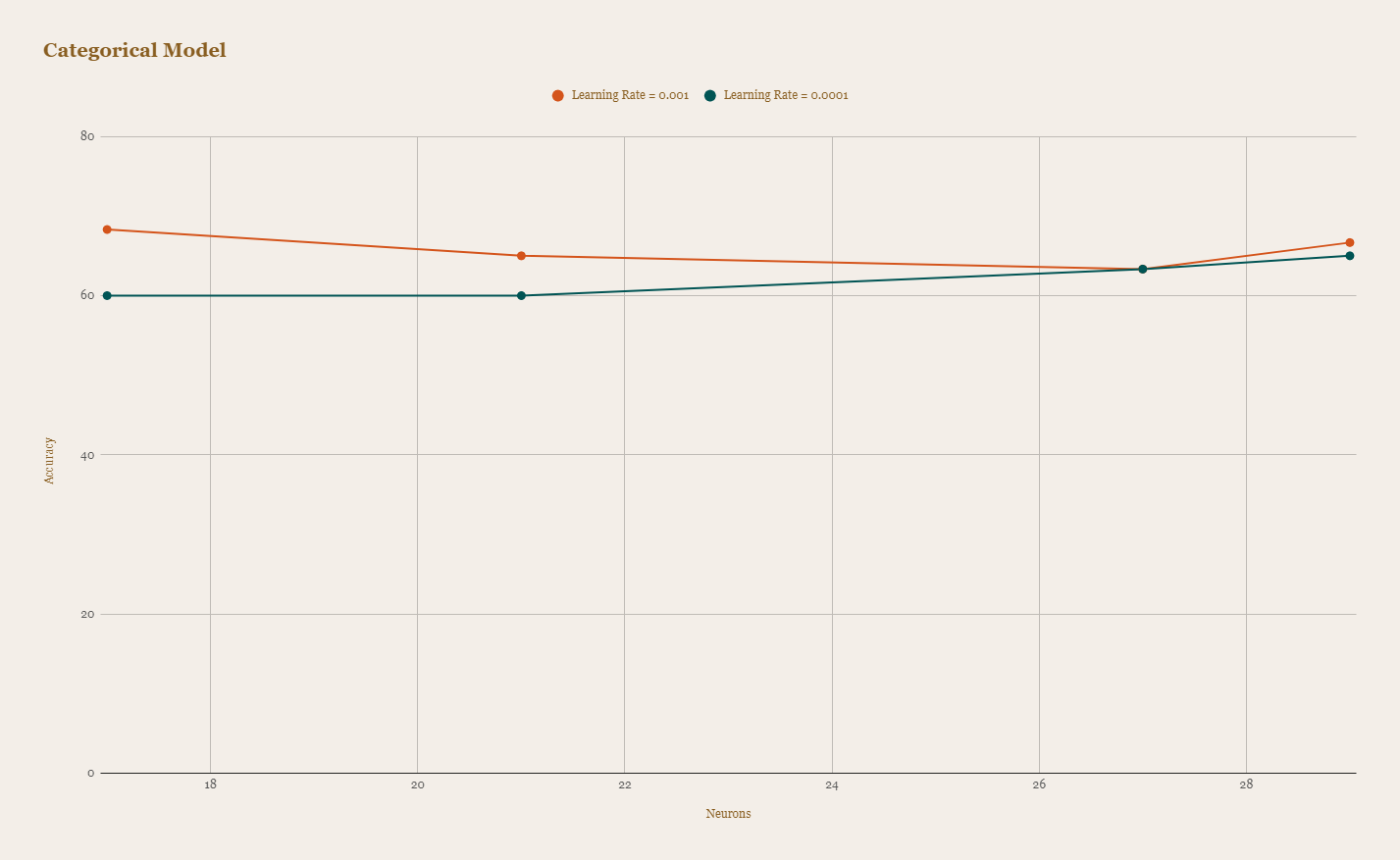
The graph above shows a comparison of classification models with different learning rates (0.001 and 0.0001) across various neuron counts.
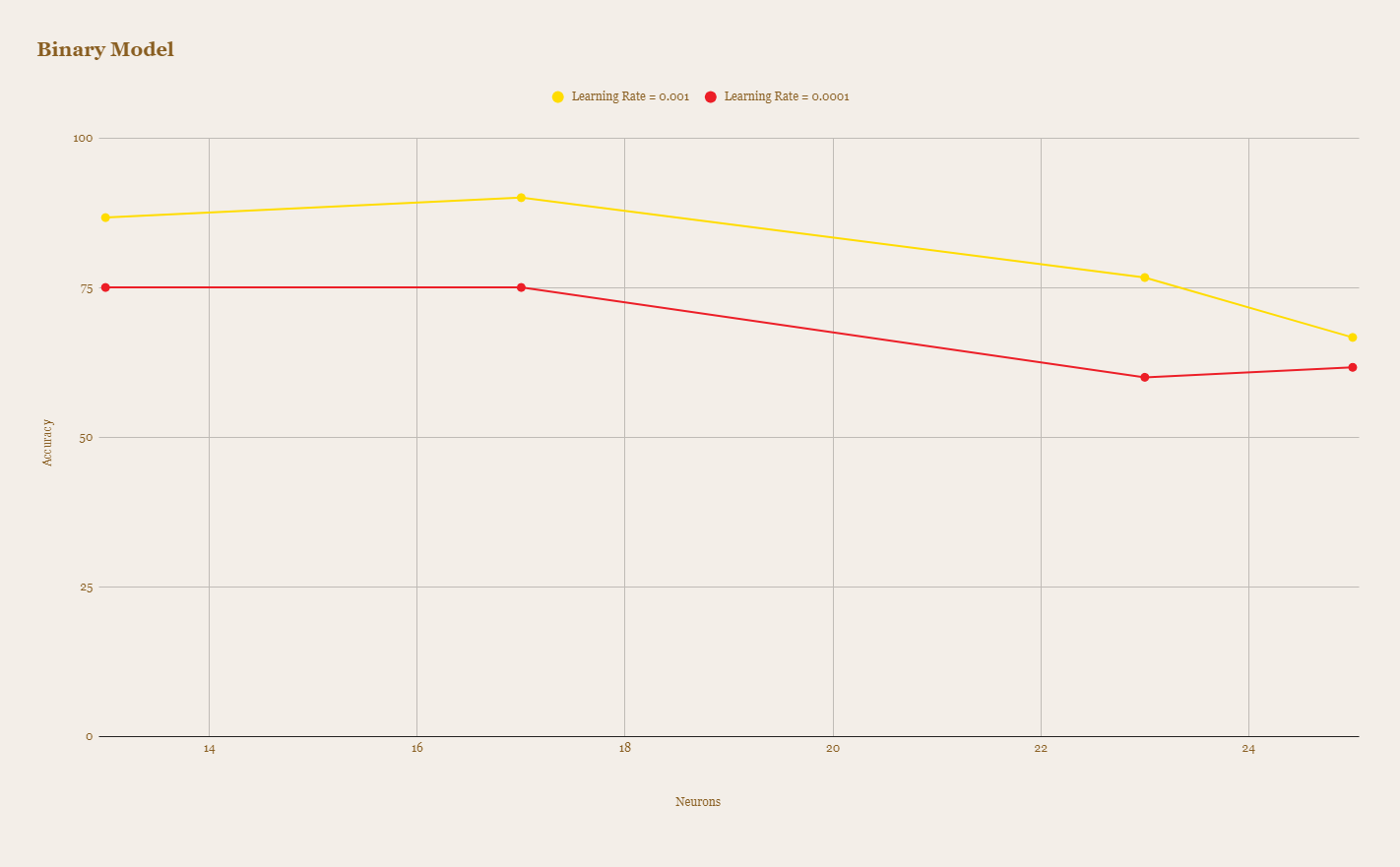
This graph displays the performance of the binary model, also comparing learning rates of 0.001 and 0.0001 across different neuron configurations.
We found that the binary model generally performed better than the classification model, especially with a learning rate of 0.001. The binary model achieves higher accuracy across different neuron counts, making it a more reliable choice for heart disease prediction in this case.
Conclusion
By choosing the Recurrent Neural Network model for the UCI repository dataset and fine-tuning its parameters, our algorithm was able to predict True Positive results more accurately compared to other models, achieving an impressive 90% accuracy.
This success in increasing the accuracy of our machine learning algorithm to detect heart disease has significant implications for medical professionals in future diagnoses. Early detection of heart disease can greatly improve survivability, and we are humbled to play a part in advancing this critical area of healthcare.